大模型投机解码(二):EAGLE 系列 — 从特征外推到动态草稿树
论文:
- EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty (ICML 2024)
- EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees (EMNLP 2024)
- EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test (2025)
作者: Yuhui Li, Fangyun Wei, Chao Zhang, Hongyang Zhang
机构: 北京大学 / Microsoft Research / University of Waterloo / Vector Institute
代码: github.com/SafeAILab/EAGLE
一句话总结: EAGLE 系列通过在特征层自回归+树状草稿+动态剪枝,在不改变输出分布的前提下,把 LLM 推理从 2.7x 一路加速到 6.5x——三代演进,每一代都精准解决上一代的瓶颈。
一、EAGLE 想解决什么问题
经典 Speculative Decoding 建立了”draft-then-verify”的范式。但这个框架的加速上限取决于两件事:
- draft 模型有多准——acceptance rate
越高,每轮验证能接受的 token 越多 - draft 模型有多快——draft 模型的开销
越低,投机解码的”本钱”越小
经典方案用同系列的小模型做 draft(比如用 7B 给 70B 当 draft),有两个困境:
1 | 困境 1:7B 给 13B 当 draft → 开销太大,不如不投机 |
Medusa 绕开了独立 draft model,直接在 target model 上加多个 MLP head 预测未来 token。但它在 token 层面独立预测,accuracy 只有约 0.6。Lookahead 用 n-gram + Jacobi 迭代,也不理想。
EAGLE 的出发点是:能不能利用 target model 自身的中间表示,训一个极其轻量的 draft 模型,在几乎零开销下达到远超其他方案的 accuracy?
下图对比了四种方法在 drafting 阶段的区别。蓝色块表示 token,橙色块表示 feature,红色边框表示 draft model 的预测:
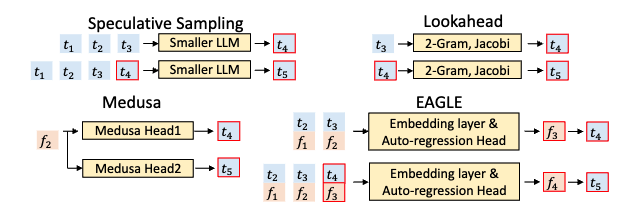
二、EAGLE:两个关键观察
EAGLE 建立在两个洞察上,它们共同指向一个比”预测 token”更好的切入点。
观察 1:特征层自回归比 token 层更简单
在 LLM 中,token 序列经过 Transformer 后变为 feature 序列——即 LM head 之前的倒数第二层隐状态。token 是离散的自然语言,变化丰富;而 feature 是连续的高维向量,在相邻 step 之间的变化更加平滑和规律。
1 | Token 层自回归: "I" → "am" → "excited" → "!" |
论文的消融实验(Figure 4)证实,在 draft model 参数量相同的情况下,预测 feature 的 speedup 为 1.9x,而预测 token 只有 1.5x。
观察 2:采样引入的不确定性是主要误差来源
即使 feature 层更好预测,有一个本质困难阻碍了进一步提升:采样过程引入的随机性。
考虑这样一个例子:
1 | 上下文:"I" |
draft model 在预测
EAGLE 的解法直截了当:把采样结果(token)也作为输入喂给 draft model。具体来说,feature 序列保持当前 step,token 序列向前平移一步:
这就是论文所说的 “feature & shifted-token”。加入 shifted token 后,draft model 能感知采样结果,speedup 从 1.9x 提升到 2.8x。
三、EAGLE 的架构与流程
3.1 Draft Model 结构
EAGLE 的 draft model 由三个模块组成:
1 | ┌──────────────────────────────────────────────┐ |
Embedding 和 LM Head 直接复用 target LLM 的参数,不需要额外训练。唯一需要训练的是 Autoregression Head:一个 FC 层(把 feature 和 token embedding 的拼接降维回 hidden_dim)加一个 Transformer decoder 层。
对于 LLaMA2-Chat 70B,可训练参数只有 0.99B——不到 target model 的 1.5%。
3.2 推理流程
下图展示了 EAGLE 的完整 pipeline。左侧是 target LLM,右侧是 draft model。上半部分是计算流程,下半部分展示了通过多次采样形成树状草稿的过程:
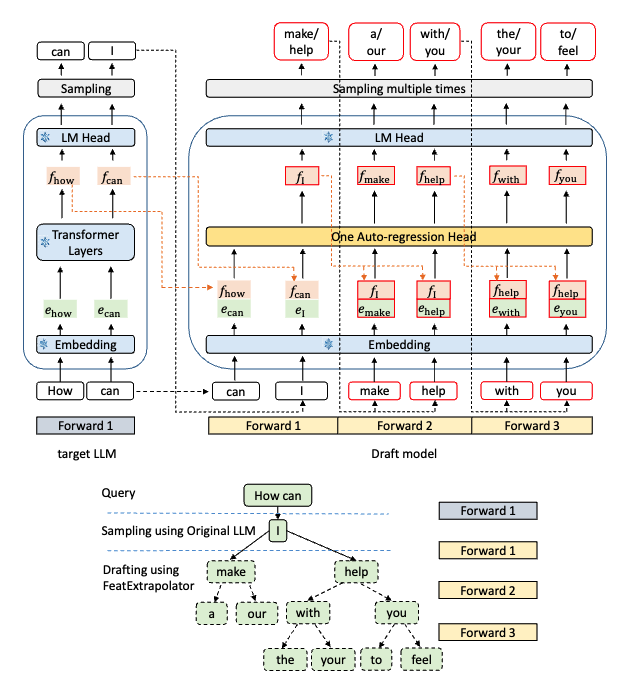
以 “How can” 为前缀来说明:
Forward 1(target model): 用 target LLM 跑 prefill,得到 feature
Forward 2(draft model): 将
Forward 3(draft model): 类似地继续展开。通过树状注意力,draft model 在每个位置采样多个候选,3 次前向就能草拟出一棵包含 10+ 个 token 的草稿树。
Verification(target model): 把整棵草稿树一次性喂给 target LLM。通过 tree attention mask,target model 一次 forward pass 即可并行验证所有路径,接受最长的合法分支。
3.3 训练
损失函数由两部分组成:
feature 回归是中间目标,token 分类才是最终目标。
训练在 ShareGPT 数据集的 68k 对话上进行。70B 模型在 4x A100 40G 上 1-2 天即可完成。7B/13B 模型甚至可以在单张 RTX 3090 上训练。
四、EAGLE 的关键设计:树状草稿
与经典 speculative decoding 的链式草稿不同,EAGLE 采用树状结构:每个位置保留多个候选 token,形成一棵 draft tree。
1 | 链式草稿: I → make → a → plan |
Tree Attention:一次 Forward 验证整棵树
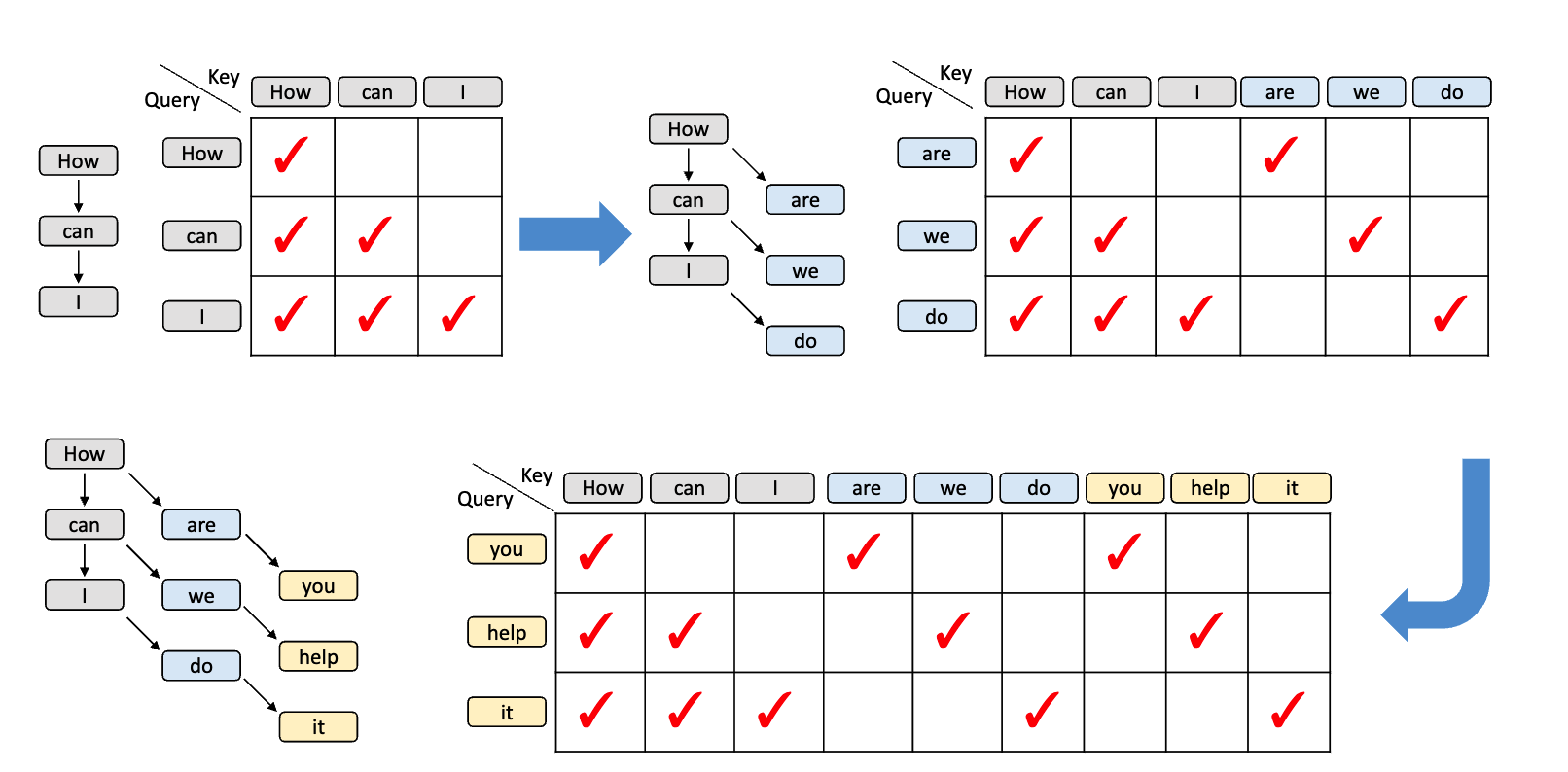
树上的多个分支物理上被展平为一维序列,但不同分支之间不应该互相看到——“a” 不是 “the” 的上文,它们是兄弟节点。Tree attention 通过定制 attention mask 解决这个问题:每个 token 只 attend 到自己从根到该节点路径上的祖先,而非展平序列中位于它前面的所有 token。
以下面这棵草稿树为例:
1 | It |
展平后送入 target model 的序列是 [It, is, has, a, the, to, good, be],对应的 tree attention mask 如下图所示。行表示当前 token(query),列表示它能看到的 token(key)。打勾表示该 query 可以 attend 到该 key 的 KV cache:
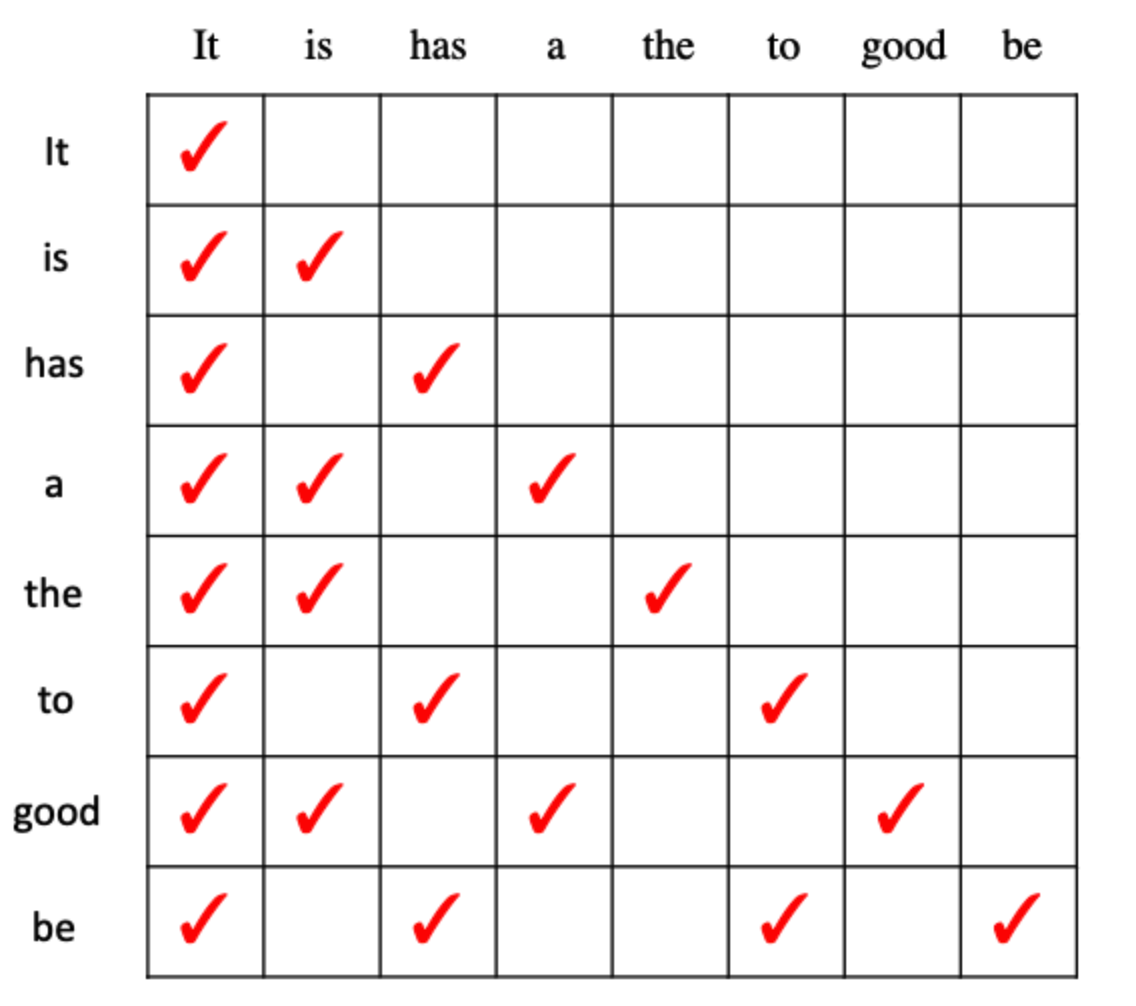
以 “good” 这一行为例,它只能看到 [It, is, a, good]——恰好是从根到 “good” 的完整路径。而 “has”、”the”、”to” 等不在这条路径上的 token 对 “good” 完全不可见,就像它们不存在一样。
这意味着在同一次 forward pass 中,target model 对每条路径独立计算了概率分布,等价于逐条路径单独验证——但只付出了一次 forward 的代价。
消融实验显示,tree attention 带来 0.6–0.8 的平均接受长度提升和 0.3–0.5 的 speedup 提升。
五、EAGLE 的实验结果
在 MT-bench 上,EAGLE 对 Vicuna 和 LLaMA2-Chat 全系列模型(7B–70B)、以及 Mixtral 8x7B 进行了评估:
| Target Model | Speedup (T=0) | Speedup (T=1) | 平均接受长度 |
|---|---|---|---|
| LLaMA2-Chat 7B | 2.78x | 2.29x | 3.71 |
| LLaMA2-Chat 13B | 3.01x | 2.78x | 3.83 |
| LLaMA2-Chat 70B | 2.97x | 2.65x | 3.77 |
| Vicuna 7B | 2.90x | 2.39x | 3.33x |
| Vicuna 13B | 3.07x | 2.65x | 3.58 |
| Vicuna 33B | 2.95x | 2.76x | 3.62 |
| Mixtral 8x7B | 1.50x | — | 3.25 |
几个值得注意的点:
- 比 Medusa 快 1.5x–1.6x,比 Lookahead 快 1.7x–2.1x
- 代码生成任务加速最高(HumanEval 上 LLaMA2-Chat 13B 达到 3.76x),因为代码模板多、可预测性强
- Mixtral 加速相对低,因为 MoE 模型每个 token 只访问 2 个 expert 的权重,验证阶段的并行优势被削弱
- 搭配 gpt-fast 量化编译后,LLaMA2-Chat 7B 在单张 RTX 3090 上达到 160.4 tokens/s
六、EAGLE-2:静态草稿树的瓶颈
下图对比了 EAGLE 与标准 Speculative Sampling 在 drafting 和 verification 两个阶段的区别。EAGLE 在 feature 层自回归(左),并使用树状草稿做并行验证(右):

EAGLE 的草稿树形状是固定的——不管上下文是什么,都用同样的树结构。这隐含了一个假设:draft token 的接受率只取决于它在树中的位置。
EAGLE-2 的作者发现这个假设不对。下一个 token 是否容易猜对,高度依赖上下文。
1 | Query: "10+2=" |
EAGLE 的静态树无法区分这两种情况——对”10+2=”它仍然在第二层放 3 个候选,浪费了确定性高时本可多猜几步的机会。下图直观地展示了这个区别:
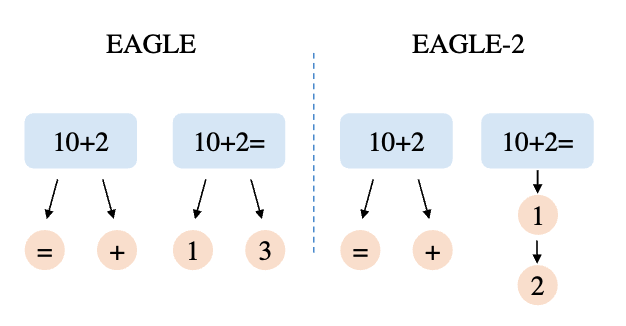
关键发现:draft model 的置信度 ≈ acceptance rate
EAGLE-2 发现了一个意外的好消息:EAGLE 的 draft model 是良好校准的。draft model 输出的 confidence score(LM Head softmax 后的最大概率)与实际 acceptance rate 高度正相关:
1 | Confidence < 0.05 → acceptance rate ≈ 0.04 |
这意味着不需要跑 target model,只看 draft model 自己的置信度就能估计每个候选 token 被接受的概率。
七、EAGLE-2:动态草稿树
基于上述发现,EAGLE-2 提出了上下文感知的动态草稿树,通过两个阶段构建:
7.1 扩展阶段(Expansion)
从 draft tree 的当前最深层选 top-
全局接受概率定义为从根到该节点路径上所有 token 接受概率的乘积:
其中
7.2 重排阶段(Reranking)
扩展完成后,树上的节点可能很多。Reranking 从所有节点中选 top-
最后,将选出的节点展平为一维序列,构造对应的 tree attention mask,送入 target model 验证。
下图展示了 EAGLE-2 动态草稿树的完整流程:先 Expand(top-2 扩展),再 Rerank(top-8 重排),最后展平为一维序列并构造 attention mask:

7.3 EAGLE-2 的优势
- 无需额外训练:直接复用 EAGLE 的 draft model,只改变草稿树的构建策略
- 无额外推理开销:置信度是 draft model 的 softmax 输出,本来就要算
- 更高的接受长度:每轮 draft-verify 产出约 4–5.5 个 token,约为标准 speculative sampling 的两倍
八、EAGLE-2 的实验结果
在 Vicuna、LLaMA2-Chat、LLaMA3-Instruct 三个系列上,EAGLE-2 在所有模型和任务上都取得了最高的 speedup:
| Target Model | EAGLE | EAGLE-2 | 提升 |
|---|---|---|---|
| Vicuna 13B (T=0) | 3.07x | 4.26x | +39% |
| LLaMA2-Chat 7B (T=0) | 3.03x | 3.51x | +16% |
| LLaMA2-Chat 13B (T=0) | 3.20x | 3.92x | +23% |
| LLaMA2-Chat 70B (T=0) | 3.01x | 3.51x | +17% |
| LLaMA3-Instruct 8B (T=0) | 2.83x | 3.29x | +16% |
| LLaMA3-Instruct 70B (T=0) | 2.72x | 3.46x | +27% |
EAGLE-2 比 EAGLE 快 20%–40%,比标准 speculative sampling 快约 2x,比 Medusa 快约 2x。
九、EAGLE-3:打破特征预测的天花板
EAGLE 和 EAGLE-2 用同一个 draft model。这个 draft model 的核心设计是在 feature 层做自回归——先预测下一步的 feature,再用 LM Head 映射为 token 分布。
然而,当作者尝试用更多数据训练 EAGLE 的 draft model 时,发现了一个令人沮丧的现象:增加训练数据几乎没有带来提升。
问题根源:特征预测约束限制了模型表达力
EAGLE 的训练损失包含 feature 回归项
1 | 好处:feature 回归让 draft model 在少量数据下就能学好 |
当数据量增加时,draft model 有能力学到更丰富的模式,但 feature prediction 的约束让它”施展不开”。
更严重的是,feature 层的自回归有一个固有问题——误差累积。Draft model 第 1 步预测的 feature
EAGLE-3 的两个改进
改进 1:去掉 feature 回归约束,直接预测 token。
EAGLE-3 移除了
但这引入了新问题:没有 feature 回归约束后,draft model 在推理时第 1 步的输出
解法是 Training-time Test:在训练时模拟推理时的多步生成过程。下图对比了三种方案的训练与推理:原始 EAGLE(有 feature 约束)、去掉 feature 约束后的退化(训练-推理不一致导致 Step 2 预测崩溃)、以及 EAGLE-3 通过 Training-time Test 解决不一致:
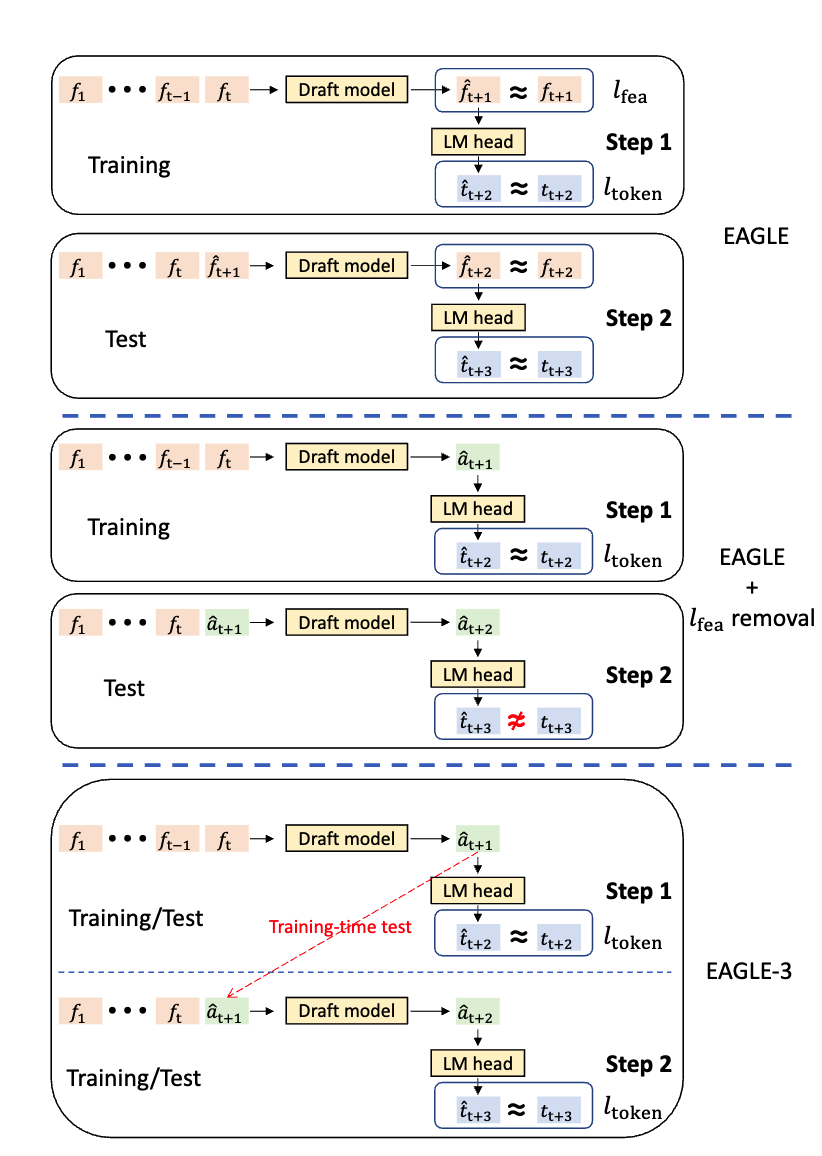
1 | 原始 EAGLE 训练: |
训练时让 draft model “吃自己的输出”做下一步预测,与推理时的行为完全一致。attention mask 也相应调整为对角矩阵(非标准的下三角),以反映树状草稿的上下文关系。下图展示了 Training-time Test 中 attention mask 的变化过程——从标准的下三角 causal mask,到模拟树状草稿的稀疏对角 mask:
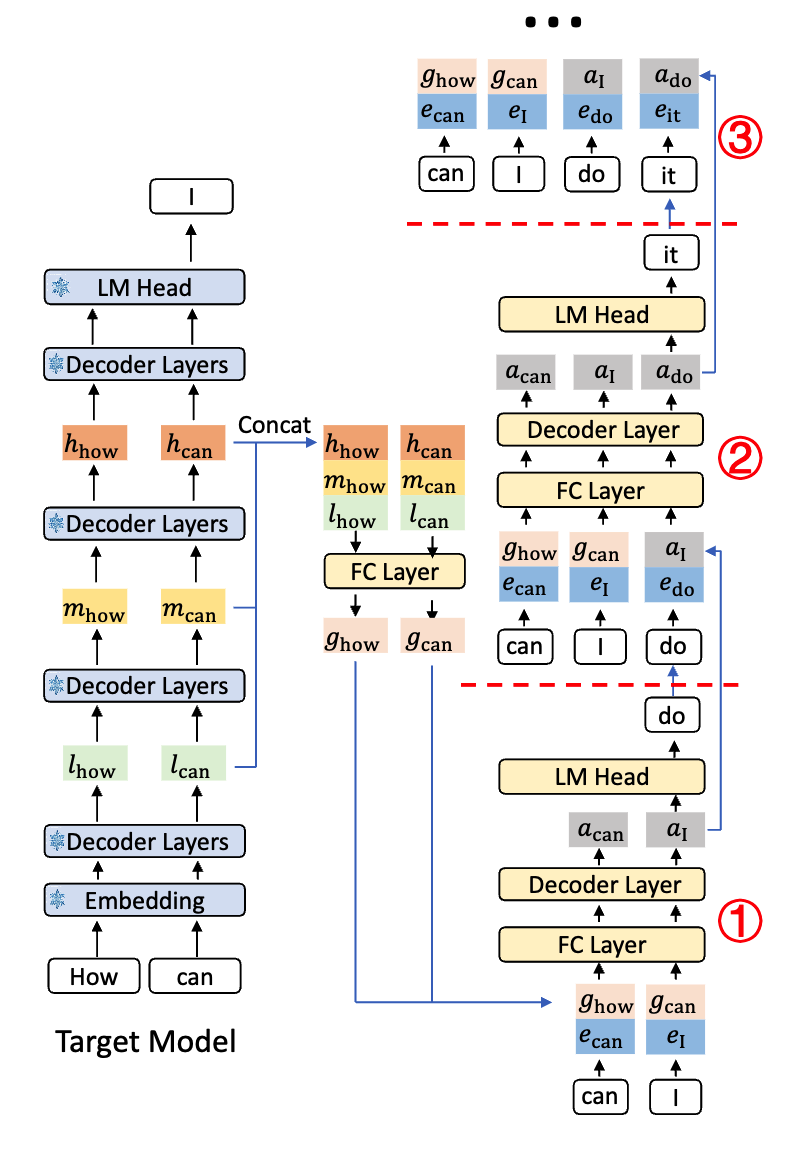
改进 2:多层特征融合,替代单纯的 top-layer feature。
EAGLE 只用 target model 倒数第二层的 feature。EAGLE-3 同时提取低层、中层、高层三个层级的 feature
这个融合 feature
Scaling Law 的出现
EAGLE-3 最令人振奋的结果是:它首次在投机解码领域展现出了 scaling law。
1 | 数据量(相对 ShareGPT) EAGLE speedup EAGLE-3 speedup |
EAGLE 的 speedup 在数据翻倍后几乎不变(因为被 feature 约束卡住了),而 EAGLE-3 的 speedup 随数据量持续攀升。这意味着,只要继续扩大训练数据,EAGLE-3 还能更快。
十、EAGLE-3 的实验结果
在 Vicuna 13B、LLaMA3.1 8B、LLaMA3.3 70B 和 DeepSeek-R1-Distill-LLaMA 8B 上评测:
| Target Model | EAGLE-2 | EAGLE-3 | 提升 |
|---|---|---|---|
| Vicuna 13B (T=0) | 4.26x | 5.58x | +31% |
| LLaMA3.1-Instruct 8B (T=0) | 3.16x | 4.40x | +39% |
| LLaMA3.3-Instruct 70B (T=0) | 2.83x | 4.11x | +45% |
| DeepSeek-R1-Distill 8B (T=0) | 2.92x | 4.05x | +39% |
| 平均 (T=0) | 3.23x | 4.44x | +37% |
EAGLE-3 的 acceptance rate 也显著提升。对比 EAGLE(使用
生产环境验证
EAGLE-3 在 SGLang 和 vLLM 两个生产级框架上得到了验证:
- SGLang(H100, LLaMA3.1-Instruct 8B, batch size=64):EAGLE-3 相比无投机解码提升 38% 吞吐量,而 EAGLE 在同等 batch size 下已无提升
- vLLM(A100, LLaMA3.1-Instruct 8B, batch size=56):EAGLE-3 仍保持 1.01x 吞吐提升,而 EAGLE 已降到 0.71x
这说明 EAGLE-3 的高 acceptance rate 使其在大 batch size 场景下仍然有效——这是投机解码走向生产的关键能力。
十一、三代演进总结
1 | EAGLE EAGLE-2 EAGLE-3 |
| 维度 | EAGLE | EAGLE-2 | EAGLE-3 |
|---|---|---|---|
| Draft 目标 | 预测 feature + token | 同 EAGLE | 只预测 token |
| 输入特征 | Top-layer feature | Top-layer feature | 多层融合 feature |
| 草稿树 | 静态 | 动态(置信度驱动) | 动态 |
| 数据 scaling | 无效 | — | 有效(首次 scaling law) |
| 训练成本 | 低(1-2天) | 零 | 中(数据更多) |
| Speedup (T=0) | 2.7x–3.5x | 3.0x–5.0x | 3.0x–6.5x |
| 大 batch 吞吐 | 衰减明显 | 衰减 | 仍有提升 |
每一代解决的核心瓶颈:
- EAGLE:解决了”draft model 太大/太慢”→ 用 feature 层自回归把 draft 压到 <1B 参数
- EAGLE-2:解决了”静态树结构浪费 token budget”→ 用置信度驱动的动态树
- EAGLE-3:解决了”feature 约束限制 scaling”→ 去掉 feature 回归 + Training-time Test
十二、思考
为什么 EAGLE 比 Medusa 好这么多? 根本区别在于对”不确定性”的处理。Medusa 的多个 head 独立预测各位置的 token,完全不感知采样结果带来的分支;EAGLE 通过 shifted token 显式把采样结果传给 draft model,让它在正确的分支上继续预测。这个设计使 EAGLE 的 accuracy 达到约 0.8,远超 Medusa 的 0.6。
EAGLE 系列的适用边界。 和所有投机解码方法一样,EAGLE 的加速在 batch size 增大时会衰减——因为大 batch 下 GPU 从 memory-bound 转向 compute-bound,验证阶段的并行优势减弱。EAGLE-3 通过更高的 acceptance rate 推迟了这个拐点,但并未消除。对于在线服务的高并发场景,EAGLE 需要与 continuous batching 等系统级优化配合使用。
与其他加速方案的关系。 EAGLE 与量化、编译优化等正交——论文展示了 EAGLE + gpt-fast 在 RTX 3090 上达到 160.4 tok/s。EAGLE 也启发了 DeepSeek-v3 的 Multi-token Prediction 预训练策略,形成了训练-推理的双向影响。
1 | Speculative Decoding ─→ 建立 draft-verify 框架 |
EAGLE 系列的三篇论文,每一篇都精准定位上一版的瓶颈,用最小的改动获取最大的收益——这种”诊断-修复”的迭代范式本身,可能比任何单项技术更值得学习。