大模型量化系列(二):SmoothQuant — 把 Outlier 从 Activation 迁移到 Weight
论文: SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
作者: Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han
发表: ICML 2023 | arXiv:2211.10438
一句话总结: SmoothQuant 承接 LLM.int8() 提出的 activation outlier 问题,但没有继续保留 FP16 outlier 分支,而是通过等价缩放把量化难度从 activation 迁移到 weight,从而让 W8A8 成为更硬件友好的部署路线。
一、LLM.int8 留下了什么问题
LLM.int8() 的关键贡献,是指出大模型 INT8 量化失败的核心原因:activation outlier。
在线性层中:
其中
LLM.int8() 的办法是绕开它:
1 | 普通 activation -> INT8 GEMM |
这个方案保住了精度,但执行路径不够干净。真实推理系统不只看 FLOPs,还要看 kernel 调度、数据搬运和融合成本。只要主路径被拆成 INT8 + FP16 两路,硬件效率就会受影响。
SmoothQuant 要回答的问题更进一步:
能不能不拆 outlier,也不保留 FP16 特殊分支,而是让主要矩阵乘都走标准 INT8?
二、预备知识:量化粒度如何影响矩阵乘
理解 SmoothQuant 之前,先看一个更基础的问题:INT8 矩阵乘里的 scale 放在哪里。
最简单的是 per-tensor 量化,整个 activation 和整个 weight 各用一个 scale:
所以:
这种方式硬件最友好,但也最怕 outlier。只要某个值特别大,整个张量的 scale 都会被拉大,普通值的有效精度就会下降。
更实用的 W8A8 路线通常会用 per-token activation + per-channel weight:
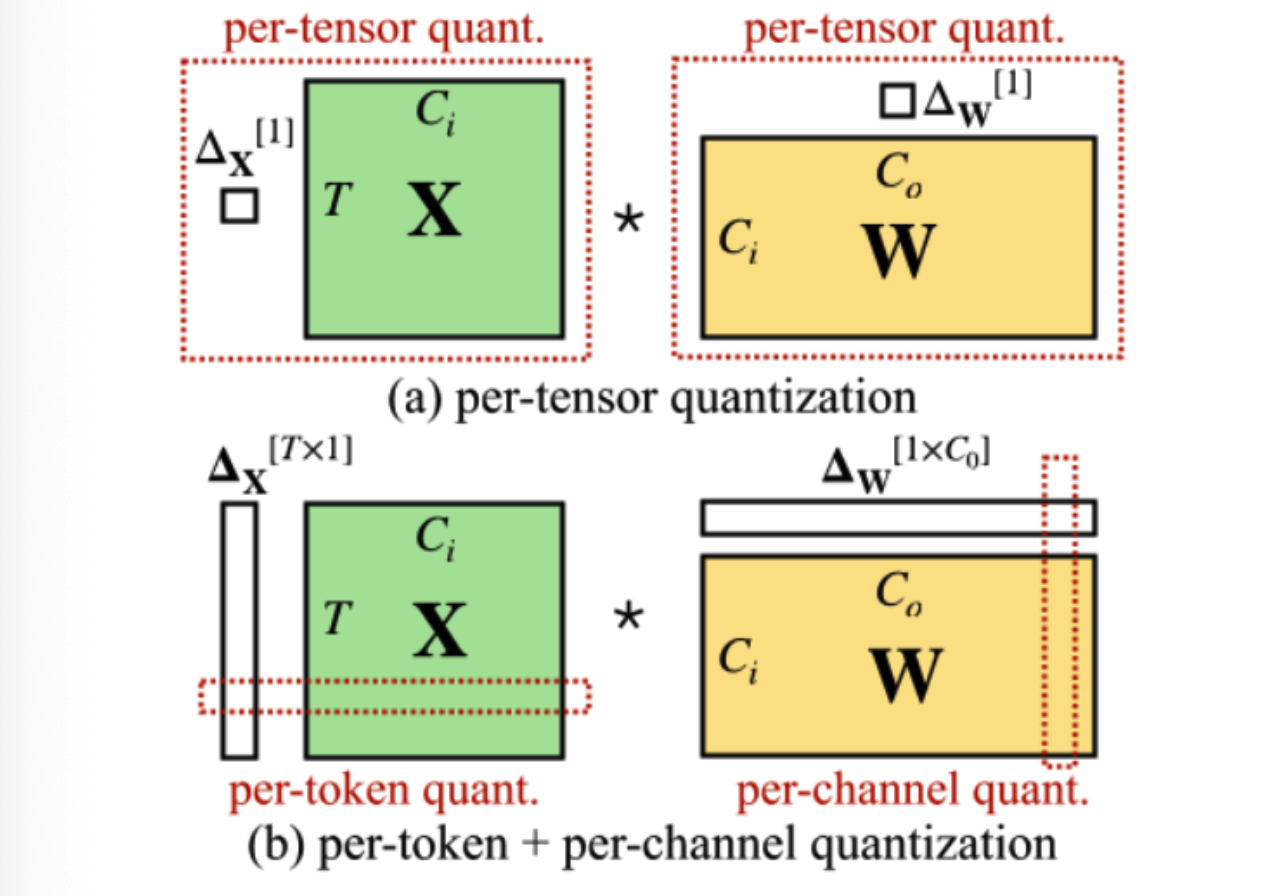
直觉上,activation 每个 token 一个 scale,weight 每个 channel 一个 scale。这样 INT8 GEMM 主体仍然可以保持干净,只是在结果外侧按 token 和 channel 补 scale:
这比 per-tensor 更稳,但还没彻底解决 SmoothQuant 关心的问题:如果 activation 的某些 hidden channel 长期有 outlier,它仍会污染对应 token 的量化范围。SmoothQuant 要处理的,正是这类 inner-channel activation outlier。
三、核心观察:Weight 比 Activation 更容易量化
SmoothQuant 的出发点很直接:
activation 难量化,weight 相对容易量化。
Activation 是动态的,依赖输入 token,运行时才出现;weight 是静态的,可以离线统计、缩放和校准。既然量化难度必须存在,更合理的选择是让它落在更可控的 weight 上。
论文图里的直觉非常清楚:
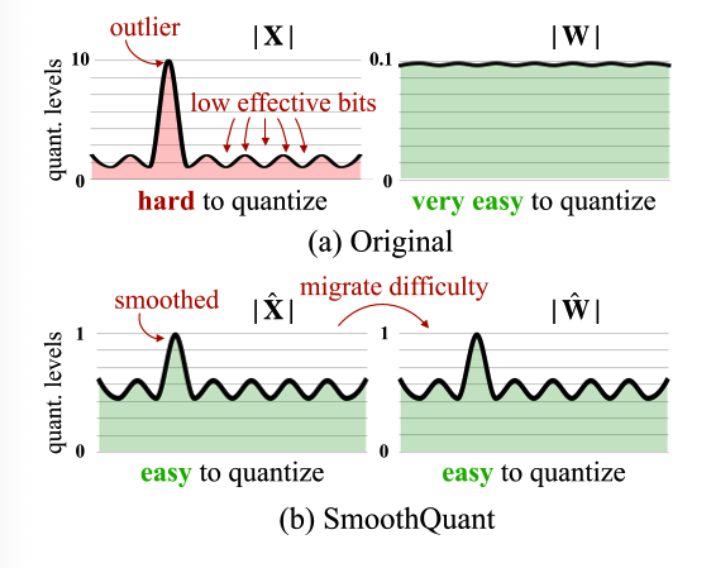
原始状态下,activation 的 outlier 拉大量化范围,普通值只剩很少的 effective bits;weight 分布相对平滑。SmoothQuant 通过缩放把 activation 变平滑,同时把对应尺度迁移到 weight。结果是:activation 和 weight 都变得相对容易量化。
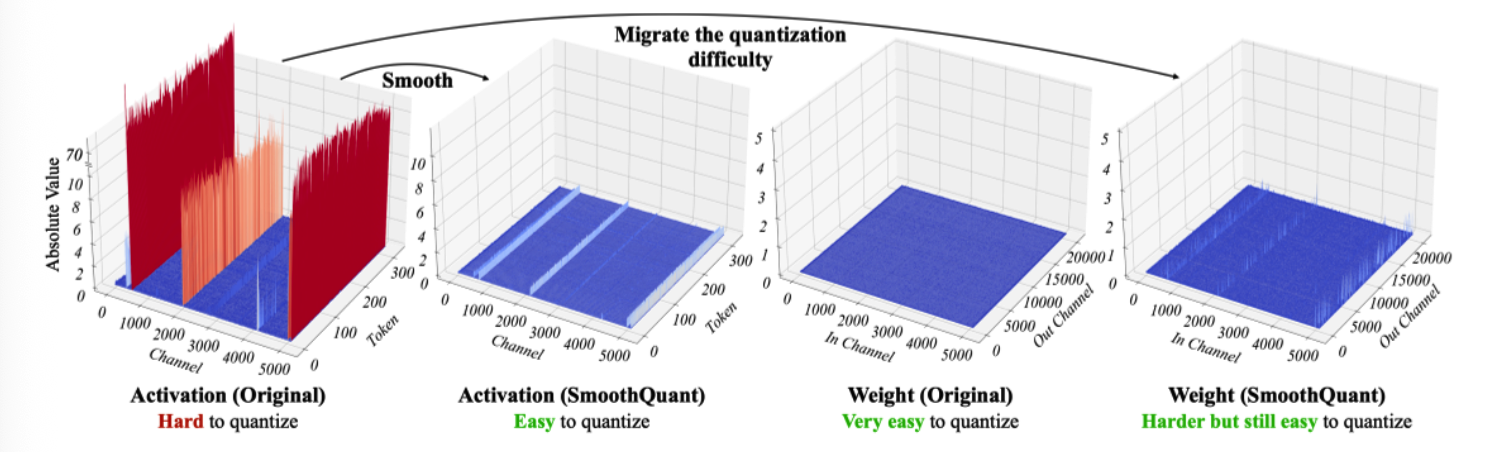
换句话说,SmoothQuant 不是删除 outlier,而是改变 outlier 压力出现的位置。
四、核心方法:等价缩放
SmoothQuant 的核心公式很简单:
更严格地写:
其中
于是:
数学输出不变,量化难度变了:
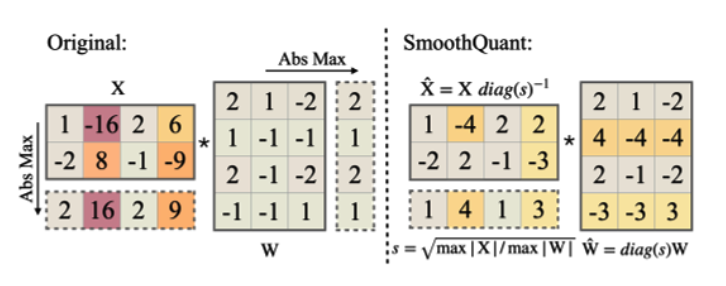
1 | 原来:X 难量化,W 容易量化 |
如果某个 activation channel 很大,就选更大的
论文用
直觉上:
越大,越多难度从 activation 迁移到 weight 越小,越多难度留在 activation - 合适的
是在两边量化难度之间找平衡
对 OPT、BLOOM 这类模型,论文中常用
五、为什么这能启用 W8A8
W8A8 指的是:
1 | Weight 8-bit |
只量化 weight,主要降低模型显存和带宽;若想充分利用 INT8 Tensor Core 或统一整数 GEMM 路径,通常需要 weight 和 activation 都进入 INT8。
但 W8A8 的难点一直在 activation。SmoothQuant 的价值,是把 activation 变得更像 weight 一样可控。
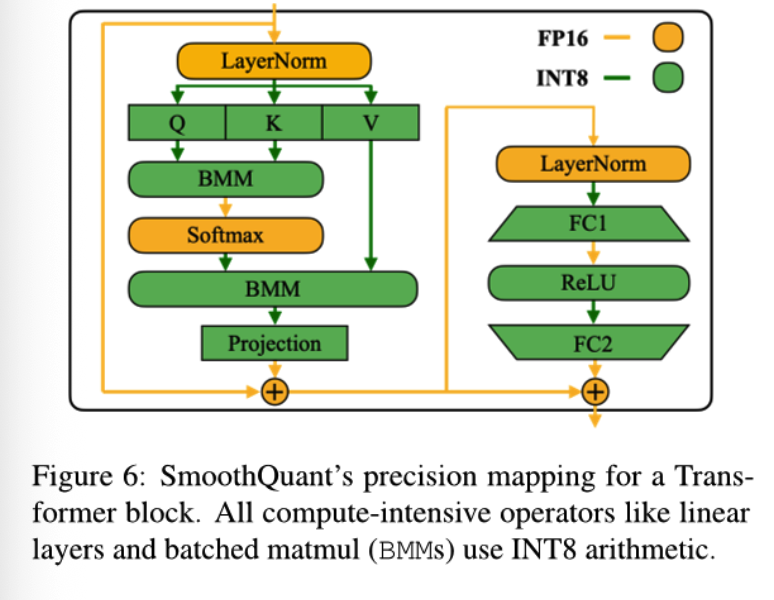
落到 Transformer block 里,主要计算密集算子可以走 INT8,LayerNorm、Softmax、残差加法等仍保留 FP16。这比 LLM.int8() 的 outlier 分支更容易映射到标准推理内核。
几条路线的定位可以这样看:
| 方法 | 典型路径 | 核心取舍 |
|---|---|---|
| LLM.int8() | INT8/FP16 混合路径 | 保住 activation outlier 精度,但执行路径不统一 |
| SmoothQuant | W8A8 友好路径 | 让主要 GEMM 走标准 INT8 |
| GPTQ/AWQ | W4A16 weight-only 路径 | 更激进压缩 weight,activation 通常保留 FP16/BF16 |
所以 SmoothQuant 不是沿着 weight-only 的极限压缩路线走,而是在回答:能不能把 activation 也纳入低精度计算主路径?
六、实验结果说明了什么
SmoothQuant 要证明的不是“INT8 能省显存”,而是:在 100B 以上大模型上,W8A8 也可以保住精度。
论文中几个结果很关键:
- 朴素 W8A8 在 OPT-175B 上几乎崩溃,WikiText perplexity 会失控。
- SmoothQuant 的 O1/O2/O3 配置基本接近 FP16,其中更激进的 O3 也能保持可用精度。
- 方法不仅适用于 OPT,也覆盖 BLOOM-176B、GLM-130B、MT-NLG 530B,以及后续版本中的 LLaMA、Falcon、Mistral、Mixtral。
- 工程上,论文报告最高约 1.56 倍加速 和约 2 倍显存降低。
更重要的是,SmoothQuant 是 PTQ(post-training quantization)。它不需要重新训练大模型,只需要用校准数据统计 activation 范围并做离线变换。对于 175B、530B 这种规模,“不训练”本身就是关键优势。
七、个人评价:更优雅,但不是终点
LLM.int8() 的思路是:
1 | outlier 很重要,INT8 搞不定,那就用 FP16 保住它。 |
SmoothQuant 的思路是:
1 | outlier 难,是因为它出现在 activation 侧; |
前者是分解问题,后者是改变问题的形态。
这也是 SmoothQuant 更优雅的地方:它没有要求硬件迁就一个特殊 outlier 分支,而是通过离线缩放,把计算图改造成更适合标准 INT8 kernel 的形态。
但它也不是终点。首先,它仍然是 8-bit 方法;很多部署场景后来更关注 4-bit weight-only。其次,它依赖 calibration,真实服务分布和校准数据差异过大时仍可能影响效果。最后,它主要处理矩阵乘法,完整推理系统还要面对 KV cache、长上下文、batching、MoE、speculative decoding 等问题。
八、站在 2026 回看 SmoothQuant
站在 2026 年看,SmoothQuant 是 W8A8 路线里的关键论文。
LLM.int8() 定义了问题:
1 | activation outlier 会毁掉朴素 INT8 |
SmoothQuant 给了一个更硬件友好的答案:
1 | 把 activation outlier 的量化难度迁移到 weight |
今天的部署权衡已经更复杂。FP8 在新一代 GPU 上成为更自然的低精度格式;KV Cache 量化在长上下文场景越来越关键;现代推理引擎通过 paged attention、continuous batching、kernel fusion、speculative decoding 改变了延迟和吞吐瓶颈。评估一个量化方法,不能只看 Linear GEMM 是否更快,还要看它和完整 serving stack 的配合。
但 SmoothQuant 留下的思想仍然重要:
量化难度不是只能被接受或删除,它可以被迁移到更容易控制的一侧。
所以这一篇和上一篇的关系可以概括为:
- LLM.int8() 证明 activation outlier 不能被忽略。
- SmoothQuant 证明 outlier 不一定必须被单独计算。
- GPTQ、AWQ 等 weight-only 方法则代表另一条更低 bit 路线。
一句话收尾:SmoothQuant 的优雅之处,不在于消灭 outlier,而在于让 outlier 出现在更容易被系统处理的位置。